Build large-scale data solutions in distributed functional blocks
Six years ago when we started Prescient, we were technologists with a vision. Big data was on the rise, and the world needed a better way to process data. At the time , the default approach was to develop data solutions in software. That method is still the default today, and it comes with its fair share of challenges:
It is not a fast process. Sure people called it “agile” because it is faster than developing hardware, but developing production software is slow.
It is expensive. Good software developers are hard to find, and you are competing with the likes of Google, Facebook, and Amazon for them.
As software gets more complicated, the process gets worse. At a prior company, our software developer lead said he was afraid of changing a single line of code, because it could cause the whole program to crash.
You’re stuck with the vendor who built it. The software could contain millions of lines of code. It is hard to understand even by the developers who wrote it. You basically get stuck with the team that developed it.
This is particularly hard for industrial companies, which faces more challenges attracting the best software talent. But what choices do companies have? Software development was and still is pretty much the only choice. This is why projects are so slow, and when they are slow, failure risks are high.
As engineers, we were used to engineering software such as Labview, Matlab Simulink, RSLogix, Cadence/Synopsys, and etc. All these have one thing in common - they support graphical programming using drag-and-drop functional blocks. Why is this approach effective? Because this allows the engineers to focus on the functionality, rather than on debugging software syntax errors. So we thought, why can’t we build large-scale, distributed data solutions this way?
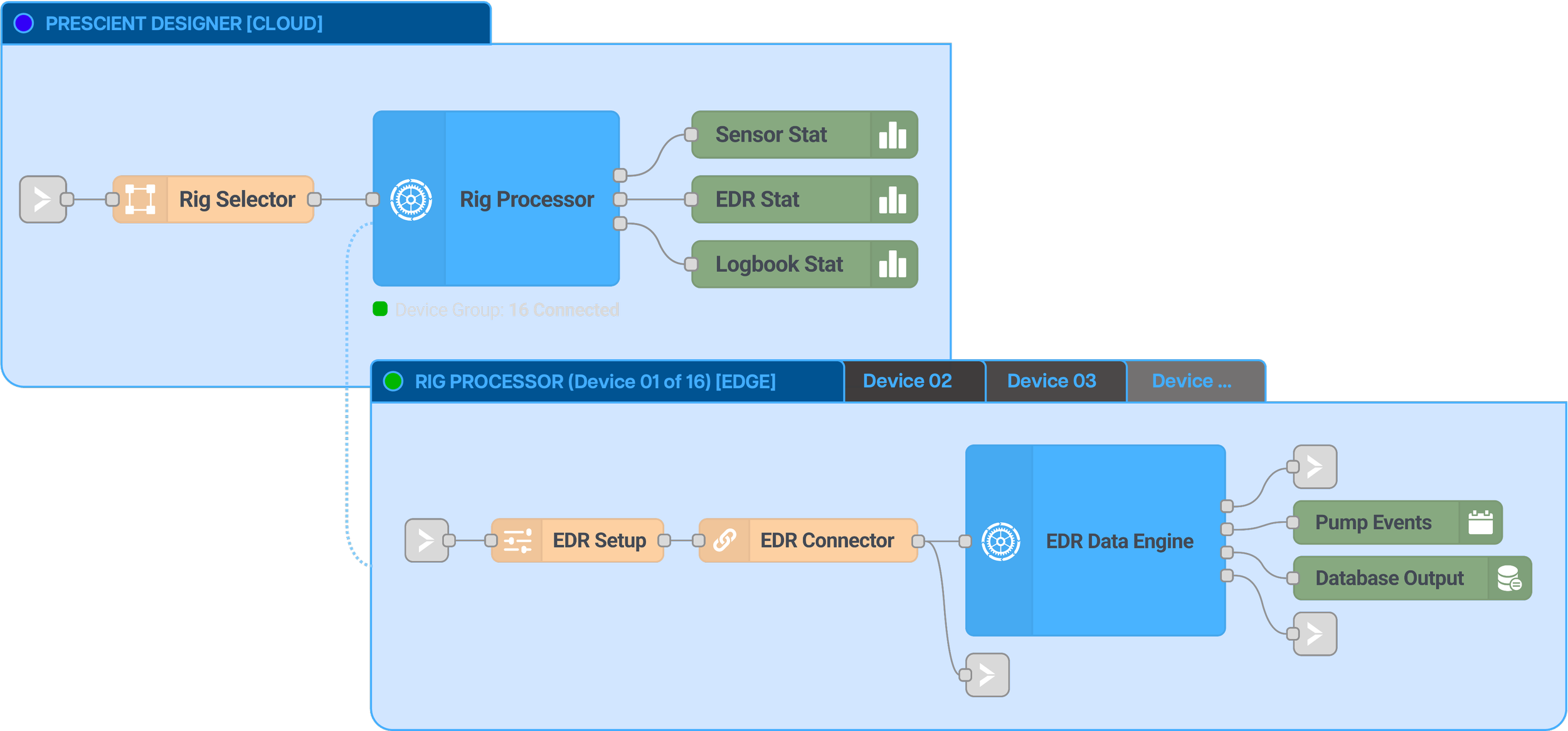
There are graphical programming software out there, but existing tools are not scalable because of the following reasons:
They are not distributed. In existing graphical programming software, design and execution happen in the same computer. Large-scale data solutions are distributed - they run at the edge, in the cloud, in hundreds to thousands of computers or virtual machines.
They don’t monitor compute load. When lots of high-speed or high-volume data is processed, a computer could crash. It is essential to monitor the compute load for every computer in the system.
They don’t meet performance requirement. While this is not the fault of the graphical programming software, it is challenging to support remote data sources and databases for high-speed and high-volume data processing. Data connectors must be designed carefully to make the system work.
By starting with open-source software, we had to build the following new capabilities:
New distributed architecture. We invented a new architecture where users can define remote execution locations directly on the function blocks. Block-to-block communication can be enabled by simple drawing wires between them, even when the blocks execute in different locations.
Compute monitoring and optimization. Memory, CPU, and disk space are monitored on every compute resource, and potential issues are predicted ahead of time.
Advanced data connectors and external resource support. We crashed our fair share of native data connectors and even databases, so we’ve rebuilt them to support high-speed and/or high-volume data processing through techniques such as caching, rate limiting, and parallelism.
Today, we’ve built solutions to process billions of data points, hundreds of millions of database queries, and execute in hundreds of locations, for critical operations that customers rely on. We have seen a marked improvement in development and iteration speed, which helps our customers to innovate faster and achieve more successful outcomes. We have validated our initial hypothesis that this is a better way to build large-scale data solutions. See how we help our customers to scale their data solutions through our customer stories.