Why are edge data pipelines hard to productionize?
An edge data pipeline transfers data from edge sources, such as machines, sensors, or historians, into a data warehouse. It often not only transfers data, but also cleans, validates, transforms, and engineers data for downstream AI, BI, and digital twins to consume. Unlike cloud data pipelines, edge data pipelines are distributed geographically and need to meet stringent on-premise security requirements.
Today, nearly every industrial company is building edge data pipelines as the value in the data will propel the next-generation growth. Yet this process is often very slow, leading to long time-to-market delays and even failed initiatives. This challenge is prevalent not only for small and medium companies, but for large enterprises as well. Some examples are listed in the below table.
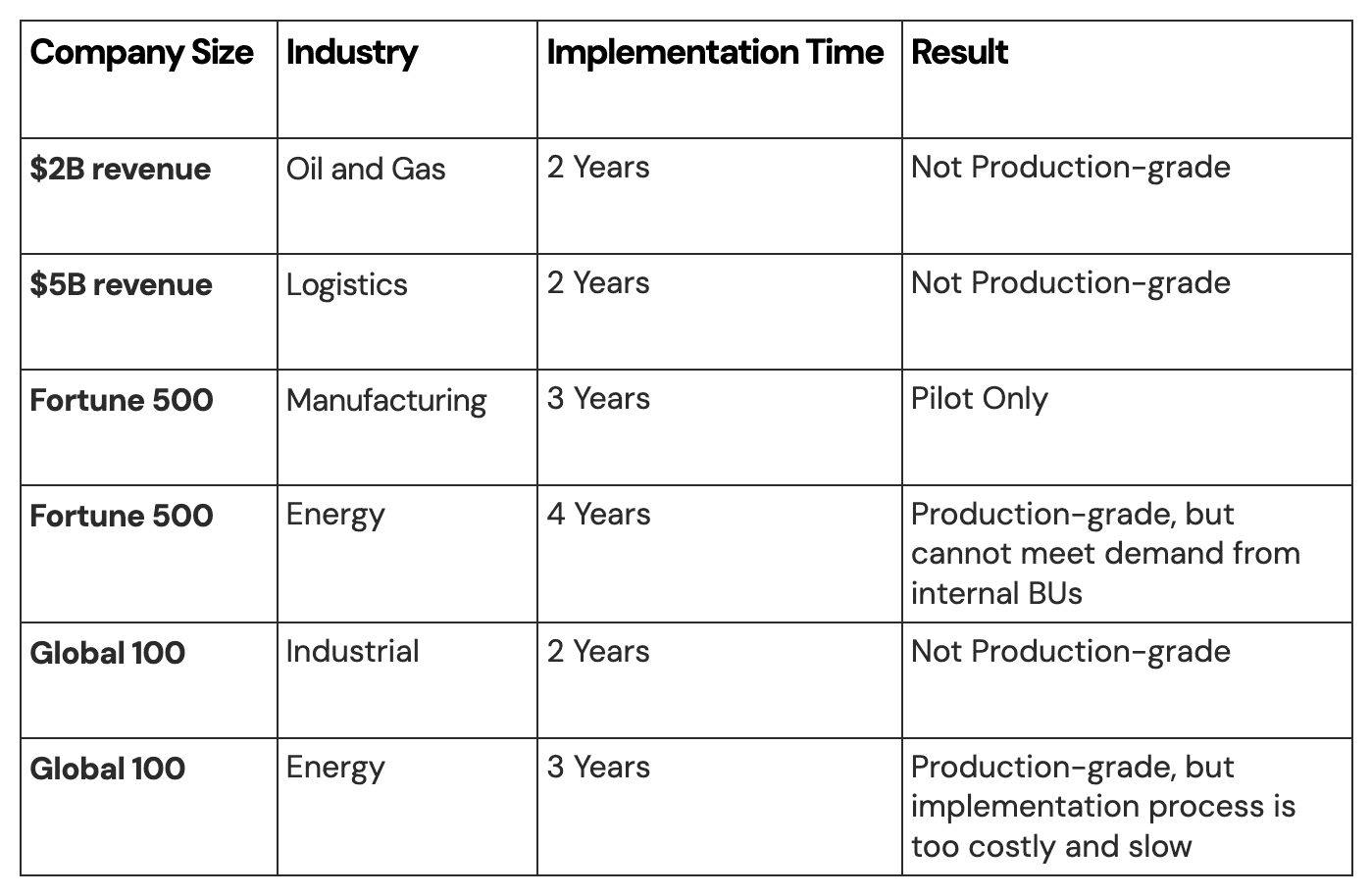
So why is this so challenging?
If it only takes a few hours to get data from a Raspberry Pi to the cloud, why does it take so long to get to production?
You may think the reason is technology, or the lack of, but it is not. There is plenty of good technology out there. The reason is the lack of know-how. Unless your team has built robust, scalable edge data pipelines before, they will need to solve a lot of performance and scaling problems along the way. There is no avoidance of the growing pain.
Case Example: Building an Edge Data Pipeline
Let’s use an example to illustrate. Say your engineering team needs to build the following edge data pipeline:
Read 200 data tags with various scan rates from PLCs
Validate, transform, and send this data to the cloud via cellular connectivity.
Sounds simple enough right? Let’s look at the know-hows your engineers need:
The Intricacies of Data Handling-Reading PLC data is easy, but doing so reliably in all conditions all the time is hard. What if the network goes down? What if the network configuration changes? What if the PLC does not respond? What if the tag name is missing? You would need to monitor all the errors that could happen, and then understand, fix, and automate the resolutions.
Scaling and Reliability across multiple Sites-Machine and sensor data are never reliable. Data could be missing, stuck, drifting, deformed, out-of-order, and etc. You will not know all the possible data errors ahead of time, so there will be a lot of trial and error to catch all the issues in the data.
Unreliable Data Connectivity -Data transmission is never reliable, so local data storage and retry mechanisms need to be built. To save cellular data cost, you would need to understand the data protocols in depth in order to minimize data consumption. For example, HTTPS headers can consume 100x more data than the PLC data itself, so how do you minimize this?
Now make sure this operation is reliable across hundreds to thousands of sites, with automated error detection and data-quality monitoring.
So for the simple data pipeline example above, it could take multiple years to get right. It might take 3 months to get 80% of the pipeline done, but the next 15% could take 12 months, and the last 5% could be insolvable without deep expertise.
For these reasons, a data pipeline partner may bring in a lot of value. This could reduce the development time from years to months, and this could be significantly cheaper when you take into account the total engineering time required. Most importantly, this would allow your team to focus on the valuable part of data transformation, namely the analytics and end applications. With a good data pipeline partner, you will be able to do more data science projects and get more value out of your data.
Key Criteria for Selecting an Edge Data Solutions Partner
To choose a good edge data pipeline partner, consider the following criteria:
Linux administration and networking expertise: Edge data pipeline runs on edge gateways and computers, and often has to deal with complex on-premise networks and security requirements, so the partner needs to have a strong understanding of embedded Linux administration and networking.
Industrial protocol and data processing expertise: Edge data is collected from machines and sensors and is physical in nature, so the partner needs to understand industrial protocols and processing techniques for physical data.
Understanding of communication protocols: While today’s engineers know how to use communication protocols such as HTTPS and MQTTS, many of them do not have a deep understanding of the fundamentals, and without such you would not be able to optimize for speed or for low data consumption.
Familiarity with Technology Stack: Using tech stack should be familiar to your engineers. We are against using proprietary technology stack because you get locked-in. Choose a partner whose product is based on open ecosystems so that the solution is not a black box to you.
Experience and Know-how: It does not matter if your partner has the best technology in the world. Instead, they should know and have solved tough data pipeline problems for other customers and can deliver high-quality, high-performance pipelines for you quickly.
Conclusion
The journey to creating efficient and scalable edge data pipelines is intricate and demands specialized skills and experience. Overcoming these challenges is crucial for harnessing the full potential of edge data in today's rapidly evolving industrial landscape.
For a deeper dive into implementing effective edge data pipelines and to explore how our expertise can benefit your organization, we invite you to visit our website or connect with us.